Abstract
Masked Image Modeling (MIM) offers a promising approach to self-supervised representation learning, however existing MIM models still lag behind the state-of-the-art. In this paper, we systematically analyze target representations, loss functions, and architectures, to introduce CAPI – a novel pure-MIM framework that relies on the prediction of latent clusterings. Our approach leverages a clustering-based loss, which is stable to train, and exhibits promising scaling properties. Our ViT-L backbone, CAPI, achieves 83.8% accuracy on ImageNet and 32.1% mIoU on ADE20K with simple linear probes, substantially outperforming previous MIM methods and approaching the performance of the current state-of-the-art, DINOv2. We release all our code and models.
Notes
Summary
Objective: Patch-level clustering agreement between teacher and masked student Encoder: ViT processes only unmasked patches. Predictor: For each MASK + pos_embed token, cross_attention aggregates visible context latents into each masked token independently. Target encoder: EMA of encoder. Processes all patches.
Implementation details
Objective
There’s a bit of nuance in “clustering”. The best way to explain this is by recalling how iBOT/DINO/DINOv2 does clustering:
- The student’s gets fed input with mask tokens, produces patch embeddings, feeds them through the DINOHead (which is composed of 3x MLP layers) and a 1 Linear Layer with out dim=65k.
- The teacher gets fed the unmasked input, produces patch embeddings, feeds them through the DINOHead and the output Linear and applies a final SK after that to the assignments. Crucially both the DINOHead and the teacher encoder weights are EMA updated.
CAPI doesn’t use the DINOHead (dropping the EMA-updated 3x MLP’s). Both student and teacher only have the final Linear layer with out dim=65k (ref1, ref2). The teacher’s encoder is EMA updated, but its output linear layer is not (it is trained by matching its latents to the prototype assignments, see ref1, ref2).
Predictor architecture
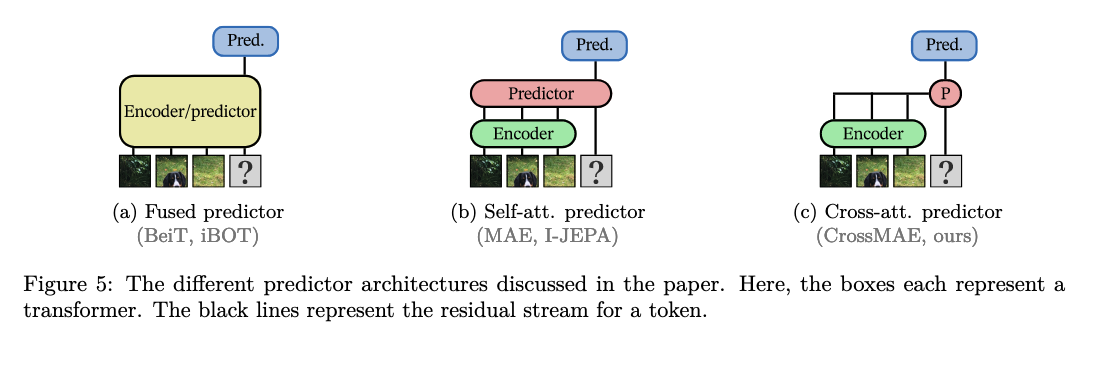
CAPI doesn’t feed mask inputs to the student encoder, only unmasked ones (like MAE). The predictor module is the one that does the heavy lifting, taking masked tokens and cross attending to unmasked latents to produce reconstructions (like CrossMAE, see its figure 3 for a better visualization).
This also has a nice property:
“[…] mask tokens do not interact with each other in the cross-attention mechanism, i.e. each prediction is independent of other positions. This alleviates the need for multiple predictor forward passes with different prediction sets, as used in I-JEPA.”
Positional collapse and position-wise SK
“While training CAPI, we observed a specific type of representation collapse as the positional encoding started outweighing the content of the patch embeddings. In the extreme case, the model learns to predict the position of the masked tokens instead of their content, resulting in a zero loss with a trivial model. […] By running the SK separately at each position in Eq. (4), we force the joint distribution of tokens over positions and clusters to be near-uniform. Uniformity of the joint distribution directly implies zero mutual information between the clustering and the targets.”
# ...
if not self.positionwise_sk:
logits = logits.flatten(0, -2)
assignments = sinkhorn_knopp(logits.detach() / self.target_temp, n_iterations=self.n_sk_iter)
tgt = assignments.flatten(0, -2).float()
# ...